

AWS concepts and ideas - ENABLING CONCURRENT WRITES ON S3 DATA LAKE
Leveraging Hive-style partitions on S3


Abstract
Amazon S3 is an object store that provides scalability to store any amount of data, and customers leverage S3 to build a data lake. Being an object store, S3 has limitations when it comes to managing concurrent writes on the same data (think transactions!). AWS continues to invest in services such as Lake Formation and S3 governed tables that solve such problems, however, this blog provides a simple framework that customers can use to enable concurrent writes.
Scenario
Cloud has enabled computing and storage at scale. As companies leverage this power and scale, they meet unique challenges that further fuel innovation. In this article, we introduce such a challenge, elaborate on one way of resolving that challenge, and demonstrate the solution through a simple example.
A customer wants to leverage Amazon S3 to build a data lake to store billions of semi-structured documents and enable multiple applications to be able to access the stored documents concurrently to enrich (update) those documents and potentially create additional documents that would be further stored on the data lake. Amazon S3 was chosen to leverage its benefits of scalability, availability and durability and cost-effectiveness.
S3 being an object store, the objects (data files) uploaded on S3 are immutable, i.e. you may upload another version of that file, however you can’t update one record within the file uploaded on S3. This means you can insert new data by uploading additional files on S3 or you can delete files from S3. However, the only way to update certain data within an S3 file is to rewrite that file after making the necessary updates.
The customer leverages AWS Glue to perform bulk updates of data on S3 and would like to overcome the challenge of effectively updating data on S3. The customer also leverages the AWS Glue data catalog as a persistent metadata store.
The Data Structure
For simplicity, consider the following data structure.
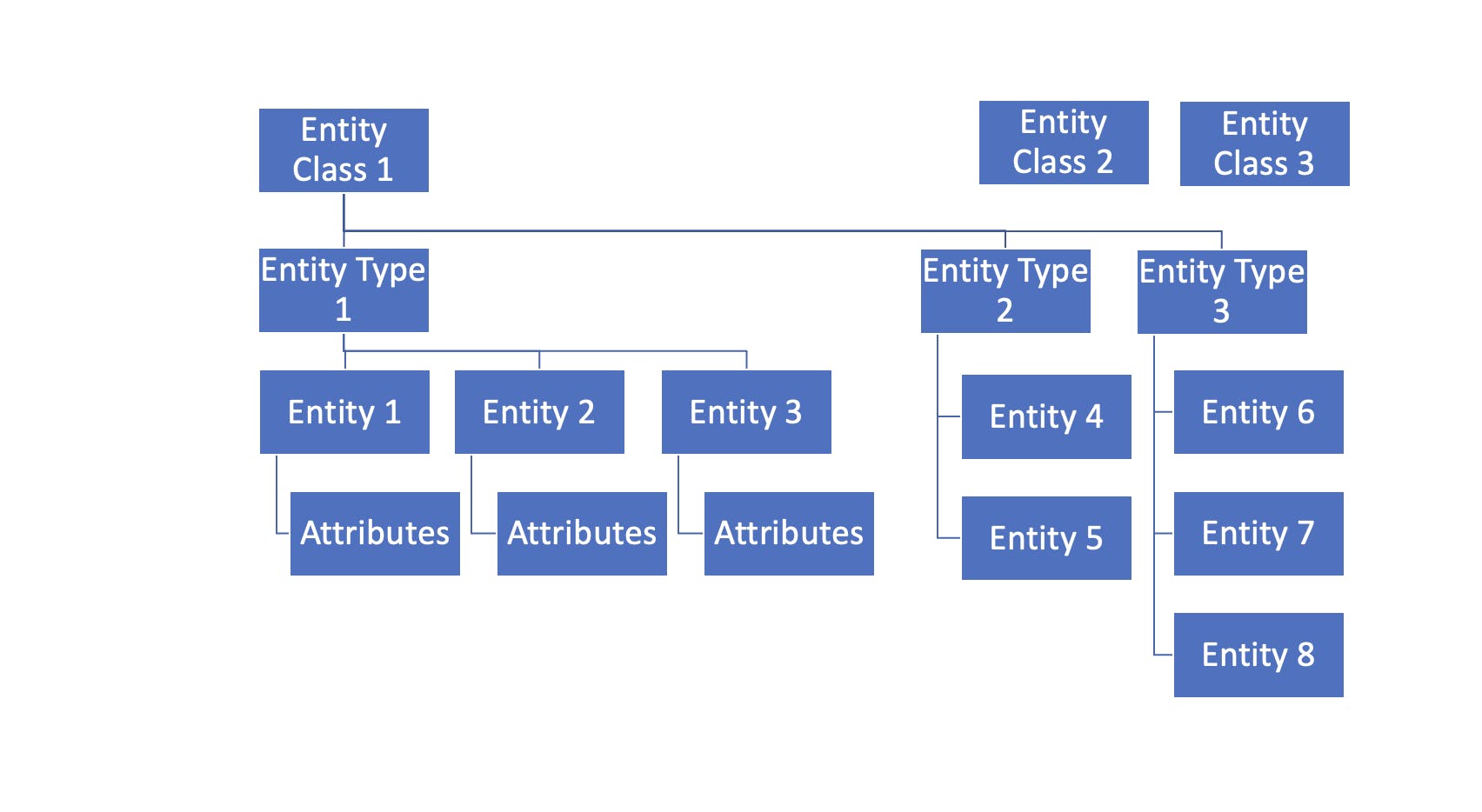
At the parent level, there is "Entity Class". There are multiple "Entity Class"
Within each Entity Class, there are multiple "Entity Types"
Within each Entity Type, there are multiple Entities
- Finally, each Entity has various attributes
To better understand this data structure, let us consider this example:
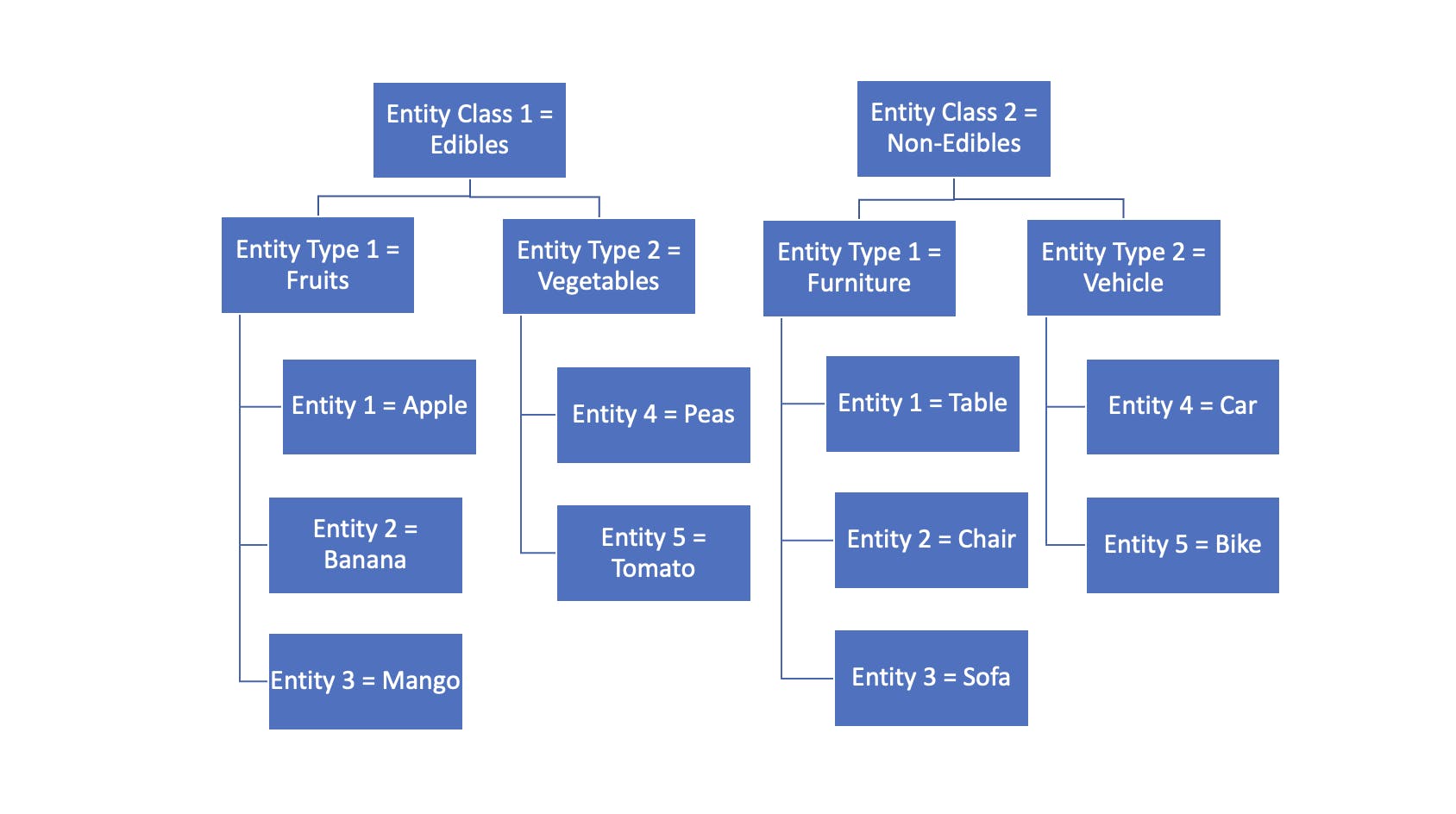
Data for each Entity is a JSON document containing attributes as key-value pairs. This data is stored in S3 in parquet format to leverage the benefits of columnar storage and compression.
The challenge
Various processes need to concurrently access any/all Entities.
Certain processes need to read data for all the Entities
Some of those processes may update one or more Entities of a particular Entity Type belonging to a particular Entity Class. However, data belonging to an entity type may never be updated by more than one process at a given time.
The Solution
Since various processes need to concurrently access any/all Entities, the potential solution of queueing up all the updates one after the other is not a desired outcome.
Some of those processes may update one or more Entities of a particular Entity Type belonging to a particular Entity Class. However, data belonging to an entity type may never be updated by more than one process at a given time. This could be achieved by a potential solution in terms of storing the data partitioned by Entity Type, such that each Entity Type has a glue catalog table. This allows concurrent writes to be performed by processes writing to different tables.
However, this solution is not acceptable, as certain processes need to read all data, and hence it is desired to store data for all the Entity Classes in the same glue catalog table.
Another option to segregate data by entity type while keeping all the data in the same glue catalog table is to use Hive-style partitions on S3. Hierarchically organizing the data would enable efficient access to the required data.
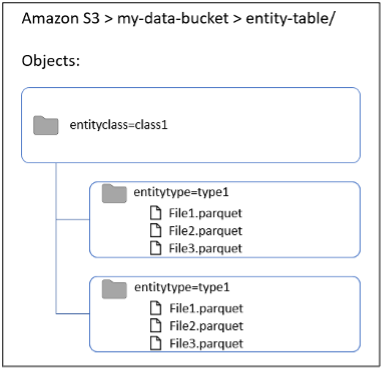
Figure: Hive-style partitions on S3
As shown in the above diagram, we can create a single glue catalog table pointing to the s3 path s3://my-data-bucket/entity-table
Underneath the folder “entity-table” we can create Hive-style partitions such as entityclass=class1/entitytype=type1
All data for Entities belonging to entitytype=type1 will be stored underneath its partition
Illustration using sample data
To develop a solution for enabling concurrent updates, we create a sample CSV file:
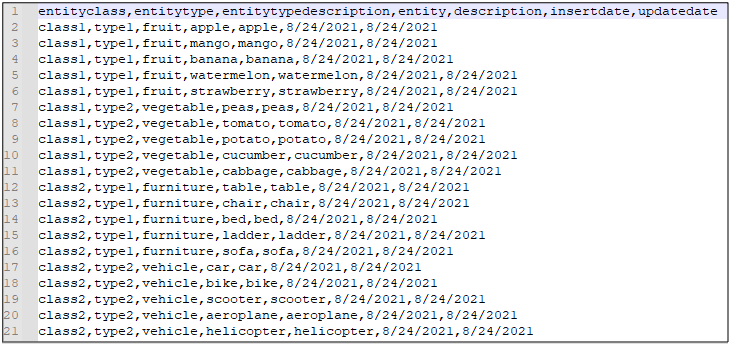
We then create a glue job to ingest this data into our glue catalog table pointing to the s3 path s3://my-data-bucket/entity-table.
Within the Glue job, we read the CSV file into a dynamic frame:
DataSource0 = glueContext.create_dynamic_frame.from_options(
format_options = {
"quoteChar":"\"",
"escaper":"",
"withHeader": True,
"separator":","
},
connection_type = "s3",
format = "csv",
connection_options = {
"paths": ["s3://bucketname/folder/file.csv"],
"recurse": True
},
transformation_ctx = "DataSource0"
)
Next, we write the dynamic frame into the target location and partition it by Entity Class and Entity Type.
DataSink0 = glueContext.getSink(
path = "s3://bucketname/folder/",
connection_type = "s3",
updateBehavior = "UPDATE_IN_DATABASE",
partitionKeys = ["entityclass", "entitytype"],
enableUpdateCatalog = True,
transformation_ctx = "DatasinkO"
)
DataSink0.setCatalogInfo(
catalogDatabase = "my_glue_db"
cataloqTableName = "my_entity_table"
)
DataSinkO.setFormat ("glueparquet")
DataSink0.writeFrame (DataSource0)
This writes the data to the glue catalog table location and is partitioned by Entity Class and Entity Type, with all data for a given Entity Type in its corresponding partition.
Accessing data from the glue catalog table
Reading all data from the glue catalog table
To read all data from the glue catalog table, simply create a dynamic frame from the catalog.
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "my_glue_db",
table_name = "my_entity_table",
transformation_ctx = "datasource0"
)
If the glue catalog table has billions of records, reading all the data is certainly not always efficient.
Reading data from specific partitions of the glue catalog table
To read data from specific partition(s), while creating Dynamic Frame, we can mention conditions to load data. This is done using a “push-down predicate”. This applies certain conditions on the partition metadata in the Data Catalog, thereby enabling us to fetch data from only specific partitions, rather than fetching all files in the dataset and then filtering in the Dynamic Frame.
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = “my_glue_db”,
table_name = “my_entity_table”,
push_down_predicate = “(entityclass==’class1’ and entitytype==’type1’)”,
transformation_ctx=”datasource0”
)
The syntax used in push_down_predicate is that of Spark SQL ‘where’ clause.
Note that sometimes there could be thousands of partitions for a glue catalog table, and when we mention push down predicate, all those partitions need to be scanned and then the predicate condition is applied. Hence to further optimize this process, we may consider using a “catalog partition predicate” along with the “push down predicate”, to reduce the number of partitions to scan through. Catalog partition predicate works on Partition Indexes. Catalog partition predicate uses a different syntax - JSQL parser syntax.
Inserting new data into partitioned glue catalog table
Assuming that you have new data in a CSV file to be inserted into the glue catalog table, you read the data from the CSV file into a Dynamic Frame, and then write Dynamic Frame by specifying partition keys in the connection options.
datasink1=glueContext.write_dynamic_frame.from_options(
frame=datasourcel,
connection_type="s3",
connection_options = {
"path":"s3://bucket/table/",
"partitionKeys": ["entityclass", "entitytype"]
},
format="parquet"
)
This inserts the data in the form of additional parquet files within those partitions.
Updating existing records within a partition
As s3 is an object storage with its objects (files) being immutable, one way to update data is by rewriting it. As for another way, AWS has recently announced additional features in Lake Formation called S3 governed tables. This feature enables us to update data in S3 transactionally. In this blog post, however, we will not dive into that capability.
Dynamic Frame also does not support an overwrite option yet. Hence we must convert the Dynamic Frame to Spark Data Frame and use partitionOverwriteMode as dynamic.
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic") datasourceM.toDF()
.write
.mode("overwrite")
.format("parquet")
.partitionBy("entityclass", "entitytype")
.save("s3://bucket/folder")
This completely rewrites the partitions within the data frame. Hence we must ensure to read the original partitions entirely and then make updates on those partitions to avoid data discrepancy.
Merging a new entity within an entity type
So far we have seen how to read data from specific partitions as well as how to update data for an existing partition.
To further build upon this, consider a scenario where we need to merge new entities with the existing entities of an entity type. This may include inserts as well as updates.
Step 1 - Reading using "push down predicate" from entityclass=class1 and entitytype=type1
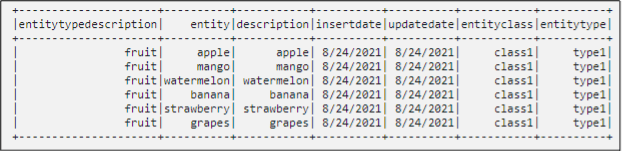
Step 2 - Reading from the iteration file that has updates

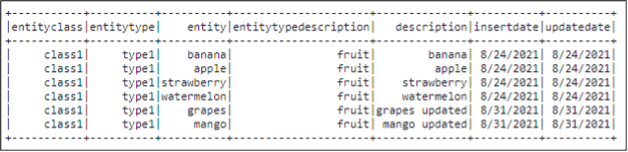
Step 3 - Merge dynamic frame by using the step-1 data as the base and step-2 data as the staging
datasourceM = datasource0.mergeDynamicFrame(
datasource1,
["entityclass","entitytype","entity"],
transformation_ctx = "datasourceM"
)
This merges the contents as shown below:
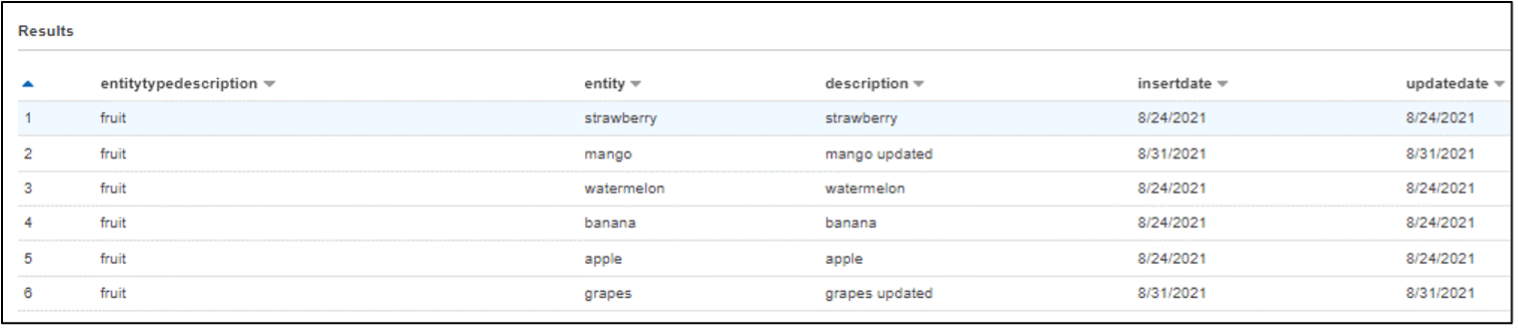
Step 4 - Write the merged dynamic frame using spark data frame overwrite mode as dynamic, as shown in the previous section
Testing Concurrent Writes to Partitioned Glue Catalog Table
In the previous section, we were able to read data from a specific partition into a Dynamic Frame, update the data as required and write the data back into the partition using overwrite feature of the Spark data frame. Now we will test to do multiple such concurrent write operations on different partitions of the glue catalog table.
To enable this, we create sample data for 4 partitions as shown below, and four glue jobs to be executed concurrently through a workflow. Each glue job will update a unique partition. Each input file has data for a unique partition.
1) Glue job for updating sample data in the partition Class 1 Type 1
Glue Job: glue_job_C1T1
Input file with updates on S3:

2) Glue job for updating sample data in the partition Class 1 Type 2
Glue Job: glue_job_C1T2
Input file with updates on S3:
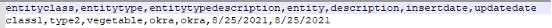
3) Glue job for updating sample data in the partition Class 2 Type 1
Glue Job: glue_job_C2T1
Input file with updates on S3:

4) Glue job for updating sample data in the partition Class 2 Type 2
Glue Job: glue_job_C2T2
Input file with updates on S3:

Next, we create a glue workflow to trigger above mentioned 4 glue jobs concurrently.
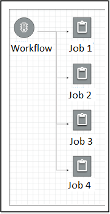
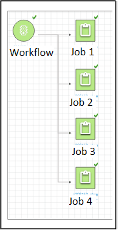
After we execute the workflow, we can verify the outcome.
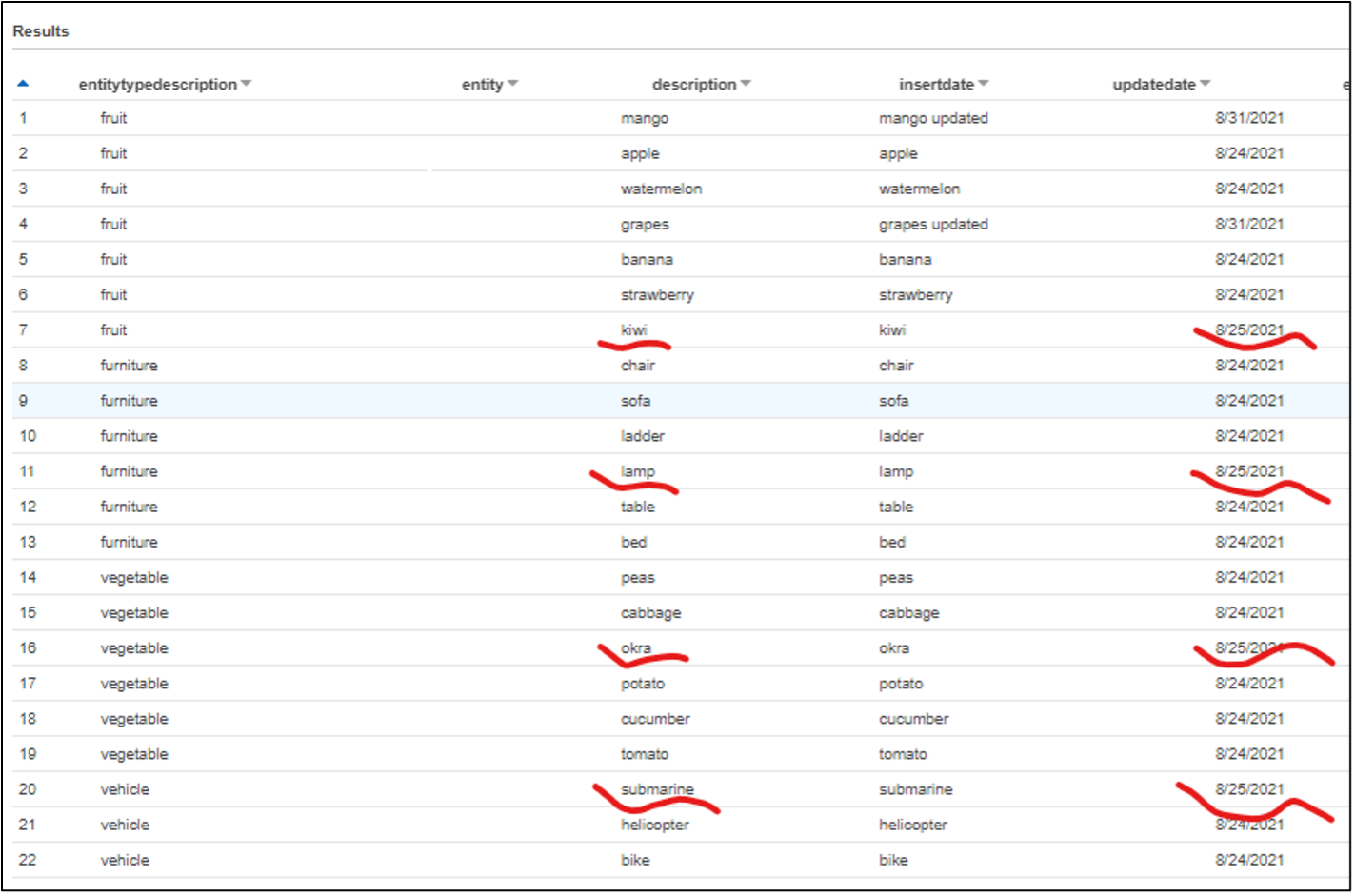
Verifying the outcome using Athena:
As shown below, data from each input file has been updated in the main glue catalog table.
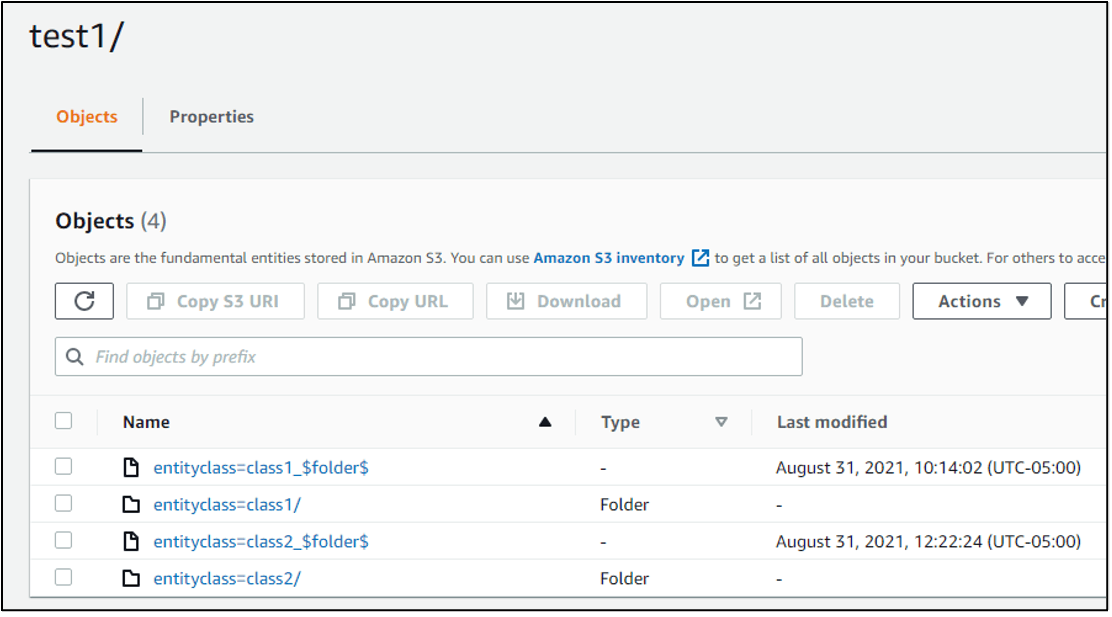
Verifying the outcome on S3:
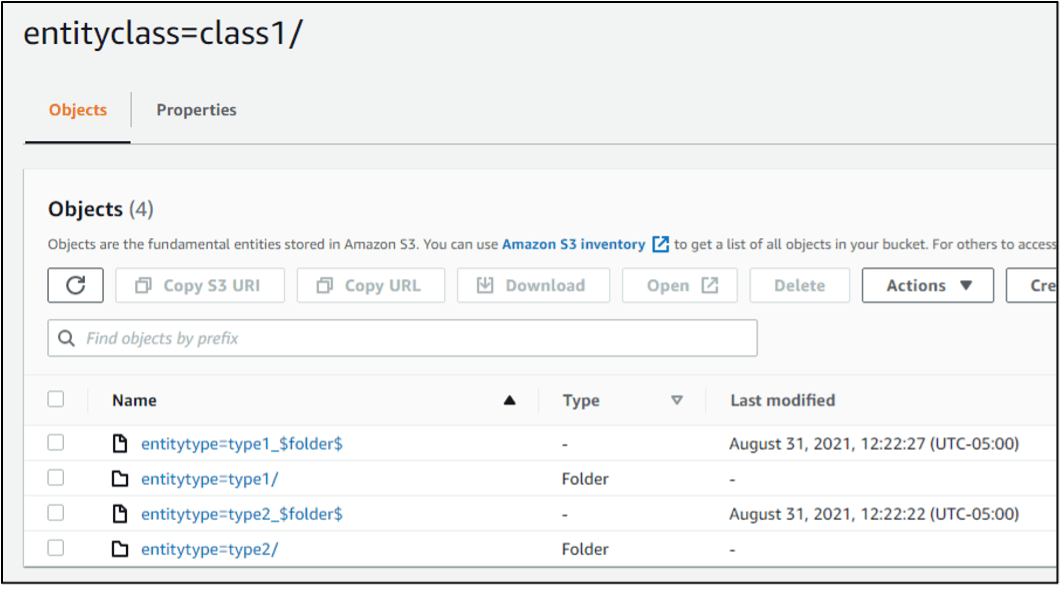
At the root path, we can see the Hive-style Partitions for entityclass=class1 and entityclass=class2
Within each partition of an Entity Class, there are further partitions of Entity Type as shown below:
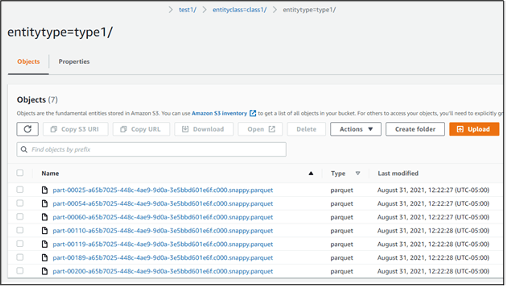
Within each Entity Type partition, we can see the data files:
Summary
Using Hive-style partitions on S3 enables us to partition the data for efficient access and concurrent operations. Amazon S3, AWS Glue catalog, Athena, and Lake Formation are powerful services that enable building data lakes to meet various requirements and needs. We look forward to additional AWS services and features in these areas and using those services and features to address various challenges that our clients are dealing with. However, till those services and features are available, we find innovative ways to help our clients in overcoming those challenges.
References
Below are some useful references for concepts covered in this blog post.
https://docs.aws.amazon.com/glue/latest/dg/partition-indexes.html
https://docs.aws.amazon.com/glue/latest/dg/workflows_overview.html
In the series of posts titled "AWS concepts and ideas", I cover some interesting topics on AWS that I encounter either as part of my projects or business development.