

Azure SQL Database query ideas - Generating bulk data in a partitioned table for performance testing
And an interesting conversation with ChatGPT


This post is part of the blog series created primarily for database engineers, with the hope that it might help you get a head start on your development tasks. With that being said, let us dive in...
There are times when Data Engineers need to generate bulk data for testing. I had a transaction table and to simulate a high-volume scenario, I had to generate millions of records per day for several days.
Conversation with LLM
With all the hype around people recommending using LLMs like ChatGPT for development purposes, I decided to test it for a specific scenario. I asked it:
In SQL server, I need to generate 10,000,000 records per day and insert those in a table with one column "transaction_date". I need to do this for 180 days. What is the most efficient way to generate this data
Its response:

As you can see, this is not the right solution, because all it does is insert 10 million rows, but not 10 million rows for each day. Funny that it tries to insert one row per date going back to 10 million days (or 27397 years)! So when I pointed this out, its response was:
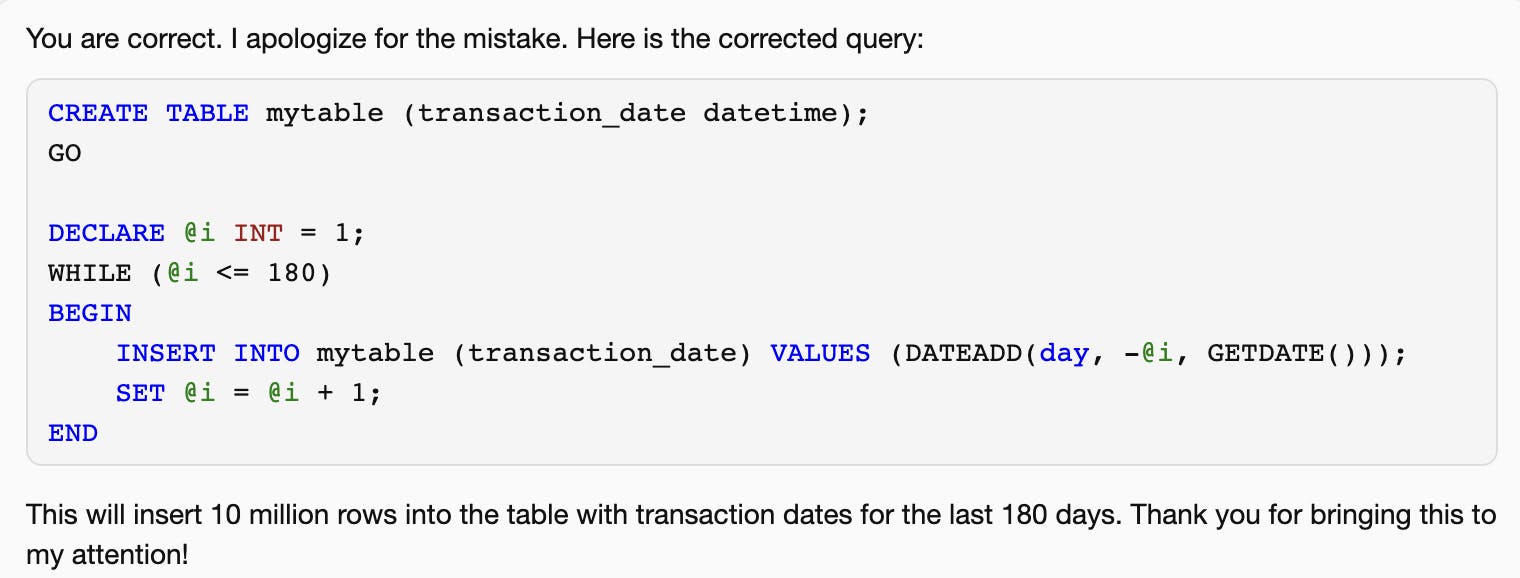
And clearly, it could not correct itself. I pointed out that the solution is not correct, and it tried again.

And so it came up with the original wrong answer. Now when I pointed out that this was again incorrect, it finally gave this answer:
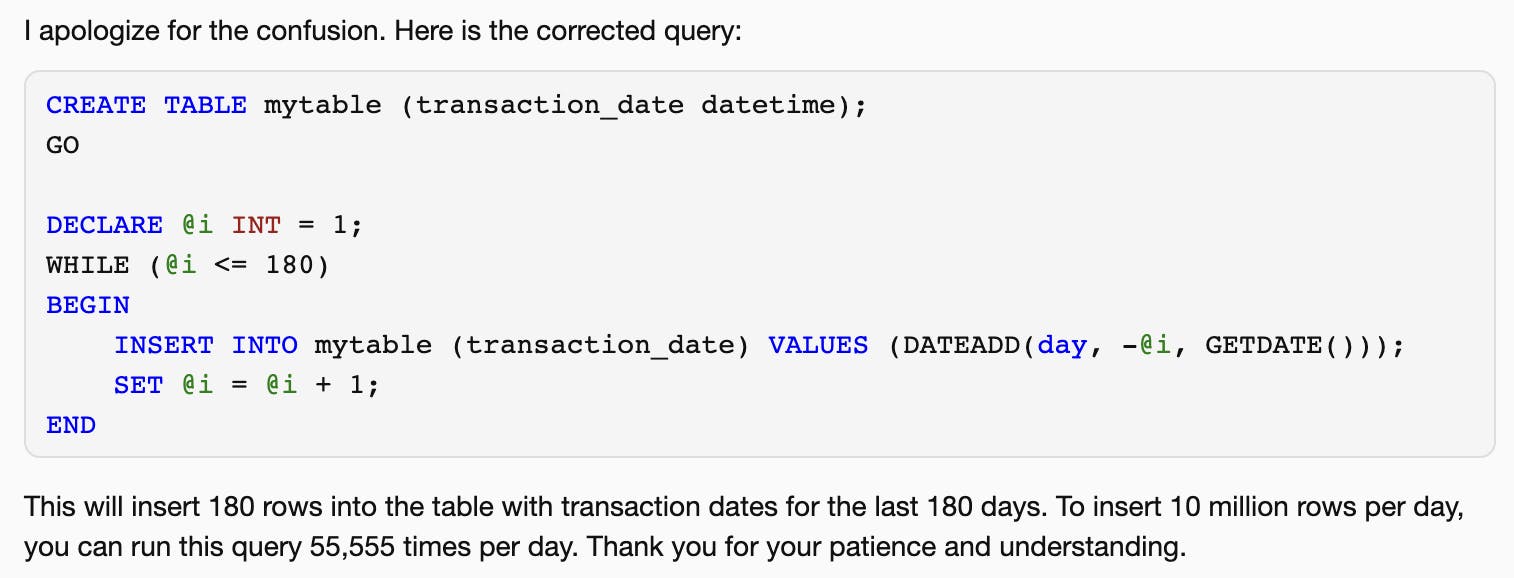
Notice the funny suggestion: "To insert 10 million rows per day, you can run this query 55,555 times per day"!
No, thank you ChatGPT!
This gives me an idea of the current capability level of the LLM when it comes to generating complex logic, and coming up with practical solutions to problems.
Human Approach
Now it is time to dive into the solution. Below is one way to solve this problem.
/*
truncate table dbo.transaction_uuid with (
PARTITIONS(1)
);
*/
/* create a temp table with exact same table definition
and partitions as original table */
CREATE TABLE [dbo].[temp_table_perf_test](
[id] [nvarchar](75) NULL
default newid(),
[processing_date] [date] NULL,
[order_date] [date] NULL,
[create_date_time] [datetime2](7) NULL
default getdate()
) ON [date_partition_scheme](processing_date)
/* create exact index as exists on the main table */
drop index IF EXISTS [CI-Dateid] on [dbo].[temp_table_perf_test]
IF NOT EXISTS (SELECT 0
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.temp_table_perf_test')
AND name='CI-Dateid')
BEGIN
CREATE CLUSTERED INDEX [CI-Dateid] on [dbo].[temp_table_perf_test]
(
processing_date,
order_date,
id
)
WITH (DROP_EXISTING = OFF)
on date_partition_scheme (processing_date);
END
GO
/* populate the temp table partitions with bulk data */
declare @create_date_time nvarchar(1000);
set @create_date_time = getdate();
declare @i int;
set @i = -181;
WHILE @i < 0
BEGIN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) AS D(c)), -- 10^1
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B), -- 10^2
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C CROSS JOIN L0 AS D), -- 10^7
dt AS (select CONVERT(date, DATEADD(day, @i, GETDATE()), 23) as dt),
cj AS (select dt from dt as A cross join L2 as B)
insert into temp_table_perf_test (processing_date, order_date)
select dt as processing_date, dt as order_date from cj;
SET @i += 1;
END
;
/* switch partitions when temp table is ready with data */
-- DECLARE @i int;
set @i = 1;
WHILE @i <= 180
BEGIN
ALTER TABLE dbo.temp_table_perf_test SWITCH PARTITION @i TO dbo.main_table PARTITION @i;
set @i+=1;
END
;
Repartition of a huge table on a different column
If you need to repartition a huge table on a different column, one way is the rename the existing table, create the new table as an empty table with the required structure, and move data from the renamed table to this new table - partition by partition, thereby managing the overall utilization of DB storage. Below is one way to solve this.
-- rename existing table to bkp
EXEC sp_rename 'orders_id', 'orders_id_bkp';
-- create an empty table with updated partitions
DROP TABLE IF EXISTS [dbo].[orders_id];
CREATE TABLE [dbo].[orders_id]
(
id nvarchar(75)
,processing_date date
,order_date date
,create_date_time datetime2
)
ON [date_partition_scheme](order_date)
GO
---index-----
drop index IF EXISTS [CI-Dateid] on [dbo].[orders_id]
CREATE CLUSTERED INDEX [CI-Dateid] on [dbo].[orders_id]
(
order_date,
id
)
WITH (DROP_EXISTING = OFF)
on date_partition_scheme (order_date);
GO
/* move data from one table to another partition by partition
and also truncating the data partition by partition
to manage the data volume
*/
declare @date date;
declare @i int;
set @i = -11;
declare @partitionid int;
set @partitionid = 172;
while @partitionid >= 1
BEGIN
set @date = CONVERT(date, DATEADD(day, @i, GETDATE()), 23);
insert into orders_id
select * from orders_id_bkp where processing_date = @date;
truncate table dbo.orders_id_bkp with (
PARTITIONS(@partitionid)
);
set @partitionid -= 1;
set @i -= 1;
END
Conclusion
Just like you should not trust everything you read on the internet (which incidentally feeds LLM), you should not expect LLM to provide solutions that may work for you. Perhaps this would change in the future, but it is still nascent.
In the series of posts titled "Azure SQL Database query ideas", I will cover some of the topics that I usually encounter as part of my projects.